

SQL Saturday Part 2: Learning About Microsoft Fabric
February 29, 2024
I’ve been digging into Microsoft Fabric recently – well overdue, since it was first released about a year ago. At the recent SQL Saturday Atlanta event I attended in early February 2024, I took the opportunity to learn from the sessions and speakers that were discussing aspects of Fabric. Shabnam Watson, John Kerski, Stephanie Bruno, and Stacey Rudoy were some of the speakers I learned from. They showed me many other resources for learning more about Fabric, including a great blog by Sandeep Pawar, also known as https://fabric.guru/
I’ve been thinking about some of my clients and how Imaginet has architected their data analytics ecosystems, or how I might choose to implement systems for new clients. For some clients, they might consider moving to Microsoft Fabric to reduce ETL times, data caching latency, or simply reducing Azure costs. I’m interested in how Fabric lines up with the capabilities of Azure Synapse Analytics, Azure Data Factory, and Azure Databricks. I believe Microsoft Fabric will likely eclipse these technologies if it hasn’t already.
Microsoft Fabric is a cloud-based data platform that provides a unified and simplified experience for data engineering, data science, and business intelligence. It is built on top of Azure Data Lake Storage Gen2 and leverages the best of breed technologies from Microsoft and the open source community, such as Spark, Delta Lake, Power BI, and SQL. Fabric allows users to create and manage data pipelines, data transformations, data models, data visualizations, and data queries using a single web-based interface, called Fabric Studio. Fabric Studio also integrates with Git, allowing users to version control and collaborate on their data projects.
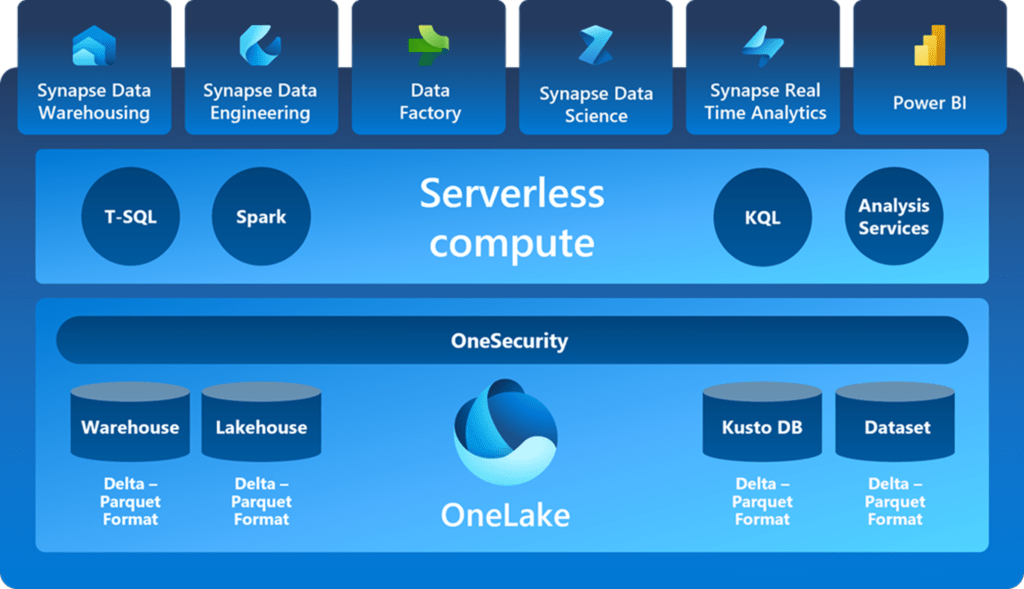
Should You Choose Fabric Over Synapse Serverless or Azure Databricks?
One of the main reasons I would choose Fabric over Synapse Serverless and Azure Databricks is that Fabric provisions all the background services for me, without having to worry about scaling, performance, or cost. Fabric automatically creates and manages Spark clusters, Lakehouse and Delta Lake tables, Power BI semantic models, and SQL query endpoints, based on the data sources and data transformations I define in Fabric Studio. This means I can focus on the data itself, and not on the infrastructure or the configuration.
Another reason I prefer Fabric is it enables Power BI DirectLake, a feature that allows Power BI to query the Delta Lakehouse tables directly, without relying on caching semantic model refreshes. This eliminates the latency of refreshing the semantic models and ensures Power BI reports are always up to date with the latest data. Power BI DirectLake also supports DAX and Q&A features, making it easy to create and explore data visualizations using natural language. Co-Pilot is now available for Power BI which extends the capabilities of its Q&A feature by using AI.
What are the Limitations of Fabric?
I think the implementation of Git integration with Fabric is somewhat incomplete. Lakehouse containers, notebooks, paginated reports, Power BI reports, and Fabric-generated Power BI semantic models (formerly known as Datasets), are all supported, but not all Fabric artifacts are. For example, only the Lakehouse container is stored in Git, not tables, folders, shortcuts, and other metadata changes.
There are several critical features not yet supported in the Fabric data pipelines, such as lacking support for data connections to use Key Vault, OAuth or Managed Service Identity (MSI) authentication. It’s not critical, but a really nice to have feature would be support for parameters for data connectors. On-premises data must use Dataflow Gen2 and a Power BI Data Gateway in lieu of the Azure Data Factory Integration Runtime agents. The lack of support for other authentication mechanisms on data sources is the biggest barrier for me to choose these pipelines over Azure Data Factory. ADF does have a connector to the Fabric Lakehouse so for now I’ll probably stay in ADF.
The Git integration is bound at the Microsoft Fabric workspace model, to a specific branch of a repo – when that branch changes, the workspace will reconfigure itself accordingly. To support multiple environments, like Dev, Test, and Prod, you would need to adopt a branching strategy for each of those environments in the repo. I’m not sure how this would affect developers having their own feature branches – I suspect they would each need their own sandbox Fabric workspace.
Instead of binding a Fabric workspace to a specific branch, I would prefer to use Azure DevOps release pipelines to deploy to different environments from a single main branch of the repo, controlled by a PR policy and unit testing. However, deployment (CI/CD) options when using Azure DevOps pipelines are incomplete, so it’s not yet possible. However, when I compare the timeline of adding developer features in Fabric to that of Power BI, I am pleased there is so much DevOps support now, and optimistic that the gaps will be filled in the near future. It seems that Microsoft is investing in the Fabric space significantly – more so than Synapse Analytics I suspect. Paul Andrew has an interesting blog post discussing this very idea: IS AZURE SYNAPSE ANALYTICS DEAD AND DOES IT REALLY MATTER?
Conclusion
I am going to look deeper at the features in Microsoft Fabric that align with other products like Databricks and Azure Data Factory (ADF) – what I heard from others at SQL Saturday Atlanta was that the Fabric implementation of data pipelines is much closer to how it is implemented in Data Factory, which was not the case for Synapse Analytics pipelines, which always seemed a few versions behind ADF. For now, I’ll probably stick with ADF. Fabric also provides some unique features and benefits, such as provisioning background services, the Lakehouse and its semantic model and SQL endpoints, Power BI DirectLake, and Git integration. However, Fabric also has some challenges and limitations, such as incomplete Git and CI/CD options, and tricky dev environments. I hope that these issues will be resolved soon, and that Microsoft Fabric will become the ultimate cloud-based data platform for data professionals and enthusiasts.
Thank you for reading! SQL Saturday was a great opportunity for me to learn more and I was excited to share this information. Make sure to subscribe to our blog to stay updated on more technology tips, tricks, and information from our team of experts.

Discover More

My Trip to SQL Saturday Atlanta (BI Edition): Part 1
My Trip to SQL Saturday Atlanta (BI Edition): Part 1 February 23, 2024 Recently, I had the opportunity to attend SQL Saturday Atlanta (BI edition), a free annual event for…

Enabling BitLocker Encryption with Microsoft Intune
Enabling BitLocker Encryption with Microsoft Intune February 15, 2024 In today’s data-driven world, safeguarding sensitive information is paramount, especially with the increase in remote work following the pandemic and the…

Primary Constructors (C# 12 Syntactic Sugar): A Guide
Primary Constructors (C# 12 Syntactic Sugar): A Guide February 8, 2024 With the introduction of .Net8 and C#12 in November of 2023, there were many significant changes to .NET and…

Let’s build something amazing together
From concept to handoff, we’d love to learn more about what you are working on.
Send us a message below or call us at 1-800-989-6022.